Entwicklungsprozess von KI-Lösungen
In diesem Kapitel erfahren Sie die relevanten Schritte und Informationen zur Entwicklung einer KI-Lösung in VISIONWEB.
YOLO
VISIONWEB ermöglicht KI-basierte Bildverarbeitung durch die Integration von Ultralytics YOLO-Modellen.
Unterstützte Aufgabentypen
Ultralytics bietet Modelle für fünf grundlegende Aufgabentypen an, in VISIONWEB werden aktuell vier davon unterstützt:
Objekterkennung: Beschreibt das Lokalisieren und Klassifizieren von Objekten in einem Bild. Objekte werden dabei üblicherweise mithilfe einer Bounding Box lokalisiert.
Orientierte Objekterkennung: Im Gegensatz zur normalen Objekterkennung sind bei der orientierten Erkennung die Bounding Boxes nicht achsenparallel, sondern gedreht, um das Objekt möglichst genau zu lokalisieren.
Instanzsegmentierung: Zusätzlich zu der groben Lokalisierung des Objekts durch eine Bounding Box werden pixelgenaue Masken des Objekts erstellt und zurückgegeben.
Klassifikation: Ordnet das gesamte Bild einer oder mehreren Klassen zu.
Ultralytics bietet für jeden der fünf Aufgabentypen fünf Modellgrößen an. Je größer das Modell, desto genauer ist es, jedoch auf Kosten der Geschwindigkeit. Zudem erfordern größere Modelle in der Regel eine umfangreichere Datengrundlage.
Neben den vier erwähnten Aufgabentypen wird in VISIONWEB zusätzlich die Codeerkennung angeboten. Diese basiert auf einem normalen Objekterkennungsmodell, das auf Lasercodes trainiert wird. Die Codeerkennung gibt die einzelnen erkannten Zeichen als erkannte Objekte zurück, sowie den gelesenen Code.
Unterstützte YOLO-Versionen
In VISIONWEB werden YOLOv8 und YOLO11 sicher unterstützt. Andere YOLO-Versionen ab YOLOv5 sind potenziell kompatibel, wurden jedoch nicht umfassend getestet.
Lizenz
Um YOLO-Modelle kommerziell nutzen zu dürfen muss eine Unternehmenslizenz von Ultralytics erworben werden, ansonsten muss entsprechend der AGPL 3.0 Software-Lizenz der Sourcecode veröffentlicht werden. Die Einhaltung der Lizenzbedingungen und eventuell notwendige Beschaffung einer Unternehmenslizenz liegt in der Verantwortung des Nutzers.
Bildaufnahme und -vorverarbeitung
Die Grundlage für die Entwicklung eines Modells ist ein ausreichend umfangreicher und qualitativ hochwertiger Datensatz. Hierfür bietet sich die Bildaufnahme der evoVIU an. Genauere Informationen zur Einrichtung der Image Source und Möglichkeiten der Datenspeicherung finden Sie auf folgenden Seiten:
Falls nötig kann vor dem Speichern der Bilder bereits eine erste Vorverarbeitung vorgenommen werden, wie Kontrast- oder Helligkeitskorrekturen.
Alle hier vorgenommen Vorverarbeitungsschritte müssen so auch vor der Eingabe der Bilder in die Inferenz durchgeführt werden.
Bildannotation
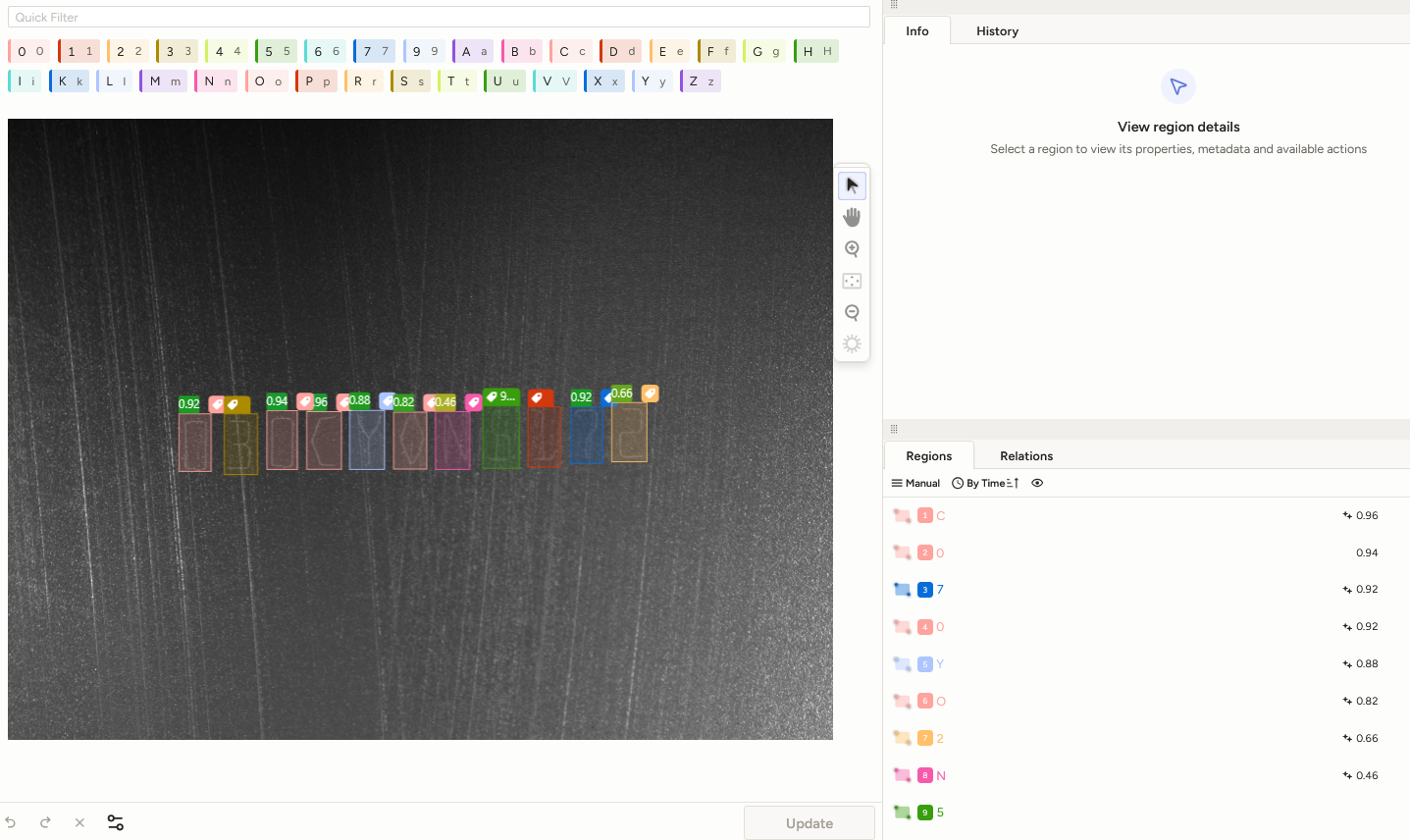
Nachdem ausreichend Daten generiert und entsprechend vorverarbeitet wurden, müssen Annotationen erstellt werden. Hierfür eignen sich Tools wie LabelStudio.
LabelStudio bietet die Möglichkeit, Bilder mit einem bereits trainierten YOLO-Modell vorzuannotieren. Dadurch kann der Labelingprozess erheblich beschleunigt werden.
Die Präzision des späteren Modells kann maßgeblich durch die Qualität der Annotationen beeinflusst werden.
Für das Training mit Ultralytics müssen die Annotationen für jedes Bild in einer gleichnamigen *.txt Datei gespeichert werden. Dabei referenziert jede Zeile ein Objekt im Bild und folgt diesem Schema:
class_id x_center y_center width height
Die Koordinaten der Bounding Box müssen auf Werte zwischen 0.0 und 1.0 normalisiert werden. Genauere Informationen zum Aufbau der Labeldatei können der Dokumentation von Ultralytics entnommen werden. LabelStudio unterstützt bereits den Export der Annotationen in ein YOLO-kompatibles Format, sodass hier keine weiteren Anpassungen mehr notwendig wären.
Modelltraining
Das Modelltraining kann in Python mit der Ultralytics-Bibliothek durchgeführt werden. Dabei gibt es auch die Option, Transferlernen zu nutzen. Hierbei können auf großen Datensätzen vortrainierte Modelle auf den eigenen Daten optimiert werden. Dies kann zu einer Beschleunigung der Trainingsgeschwindigkeit und insbesondere bei einer geringen Datengrundlage zu einer Stabilisierung des Modells führen.
Das Training kann über eine YAML-Datei konfiguriert werden. Dabei können Hyperparameter wie die Epochenanzahl oder Lernrate gesetzt werden. Zudem können Parameter zur Datenaugmentierung angepasst werden. Genauere Information zu Konfiguration und Durchführung des Trainings sind in der Ultralytics Dokumentation zu finden.
Ultralytics führt eine automatische Vorverarbeitung der Bilder durch. Dabei werden die Bilder unter Verwendung einer Letterbox auf die angegebene Eingabegröße skaliert.
Es ist zu empfehlen den Datensatz in Trainings-, Validierungs- und Testdaten zu unterteilen. Eine übliche Aufteilung sind dabei:
70% Trainingsdaten
15% Validierungsdaten
15% Testdaten
Die Pfade zu den einzelnen Datensätzen und die Definition der möglichen Klassen, werden wiederum in einer YAML-Datei angegeben. Das Modell wird dann auf dem Trainingsdatensatz trainiert und währenddessen immer wieder anhand des Validierungsdatensatzes validiert.
Es empfiehlt sich das Modell nach abgeschlossenem Training auf dem Testdatensatz zu validieren. Auch hierfür bietet Ultralytics eine Methode an.
Modellexport und Quantisierung
Für die Nutzung von YOLO-Modellen auf einer evoVIU gibt es zwei Möglichkeiten. Die Durchführung der Inferenz auf der CPU mit einem ONNX-Modell, oder alternativ auf der NPU mit einem TFLite-Modell. Die Nutzung der NPU ermöglicht eine erheblich beschleunigte Inferenz, setzt jedoch eine Quantisierung voraus, die zu Präzisionsverlusten des Modells führen kann.
ONNX
Falls das Modell mit Ultralytics trainiert wurde, muss das daraus resultierende PyTorch-Modell (.pt) in das ONNX-Format exportiert werden. Ultralytics bietet hierfür eine Exportfunktion an.
TFLite
Für eine Nutzung des Modells auf der NPU muss das Modell in das TFLite-Format exportiert und dabei uint8-quantisiert werden. Dafür muss das De-Girum Repository verwendet werden.
Nachdem das Repository geklont und aufgesetzt wurde, können über einen CLI-Befehl die Quantisierung und der Export des Modells gestartet werden. Für den Quantisierungsprozess werden Bilder zur Kalibrierung benötigt. Hierfür kann dieselbe YAML-Datei angegeben werden, die für das Training verwendet wurde.
Es werden mehrere TFLite-Modelle erstellt. Für den Einsatz auf der evoVIU ist ausschließlich die Datei best_full_integer_quant.tflite relevant.
Möglicher CLI-Befehl:python3 dg_export.py --weights path/to/your/best.pt --format tflite --quantize --data path/to/your/data.yaml --img-size 640 --max_ncalib_imgs 648
Inferenz in VISIONWEB
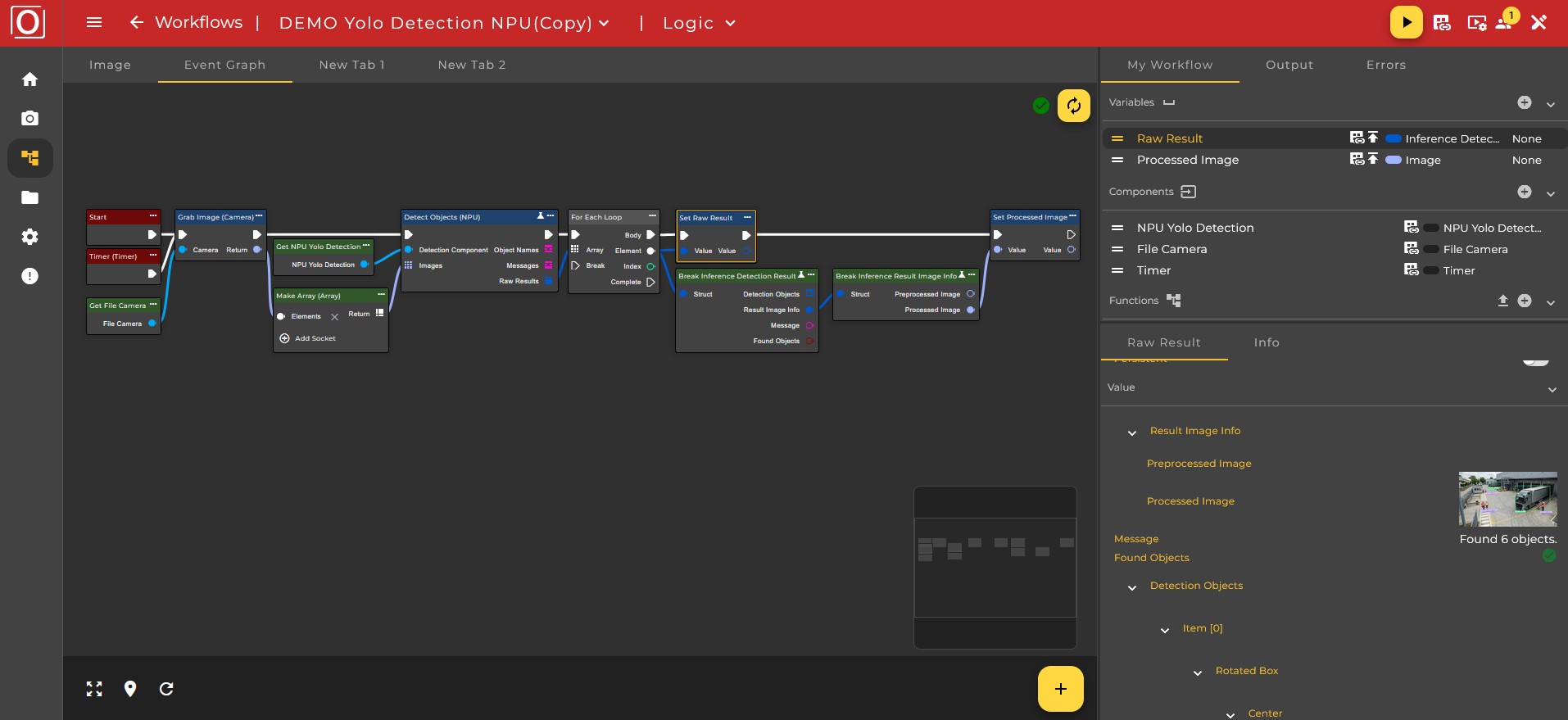
Für jede Aufgabe und Modellart gibt es entsprechende Knoten und Komponenten im Workflow. Die Knoten und Komponenten befinden sich jeweils unter Applications|ONNX oder Applications|NPU.
Komponenten
Über die Komponenten können Einstellungen für die Inferenz und Nachbearbeitung der Ergebnisse getroffen werden. Verfügbare Komponenten sind:
ONNX Yolo Detection
NPU Yolo Detection
ONNX Yolo Classification
NPU Yolo Classification
ONNX Yolo Segmentation
NPU Yolo Segmentation
ONNX Code Detection
NPU Code Detection
Die unterschiedlichen Komponenten ähneln sich in den grundlegenden Einstellungen, variieren aber zu Teilen entsprechend der durchzuführenden Objekterkennungsaufgabe.
Inference Settings
Model File Path: Gibt den Pfad zu dem ONNX- oder TFLite-Modell an, das für die Inferenz genutzt werden soll.
Achten Sie darauf, dass die gewählte Komponente und das Modell in Bezug auf Aufgabenstellung und Hardware übereinstimmen.
Number Of Threads: Bestimmt die Auslastung der NPU/CPU.
Output Parsing Settings
Oriented Boxes (Detection): Gibt an ob orientierte oder normale Objekterkennung durchgeführt werden soll.
Es muss entsprechend das passende Modell angegeben werden!
Confidence Threshold: Gibt den minimalen Confidence-Wert an. Detektionen unterhalb dieses Werts werden aussortiert. Ein üblicher Wert ist 0.6.
Mask Threshold (Segmentation): Gibt an ab welchem Confidence-Wert Pixel als Teil der Maske angesehen werden. Ein üblicher Wert ist 0.5.
IoU Threshold (Detection, Segmentation): Gibt an wie hoch die Überlappung zwischen zwei erkannten Objekten sein darf. Dadurch werden Detektionen die das gleiche Objekt referenzieren aussortiert. Ein üblicher Wert ist 0.45.
Maximal Number Of Detections: Gibt an wie viele Detektionen maximal zurückgegeben werden.
Processed Image Settings (Detection, Segmentation)
Diese Einstellungen betreffen die Ausgabe des verarbeiteten Bildes. Auf diesem werden die erkannten Objekte, deren Confidence-Werte und Klassen angezeigt. Aus Übersichtsgründen kann die Beschriftung der erkannten Objekte deaktiviert werden. Eine Bounding Box wird immer eingezeichnet. Bei der Klassifikation wird nichts eingezeichnet, da das ganze Bild klassifiziert wird.
Npu Inference Settings (NPU)
Einstellungen, die nur bei der Inferenz auf der NPU relevant sind:
Bilinear Interpolation (Segmentation): Interpoliert die Masken der erkannten Objekte. Das führt zu genaueren Konturen.
Classes File Path: Pfad zu einer JSON-Datei, die die möglichen Klassen mit Id und Namen definiert. Der Aufbau der JSON sollte diesem Format entsprechen:
CODE{ "categories": [ { "id": 0, "name": "dog" }, { "id": 1, "name": "cat" }, ... ] }
Alle Klassen, auf denen das Modell trainiert wurde, müssen in der JSON-Datei enthalten sein!
Return Preprocessed Image: Gibt an, ob das vorverarbeitete Bild zurückgegeben weden soll. Aus Laufzeitgründen ist diese Option standardmäßig deaktiviert.
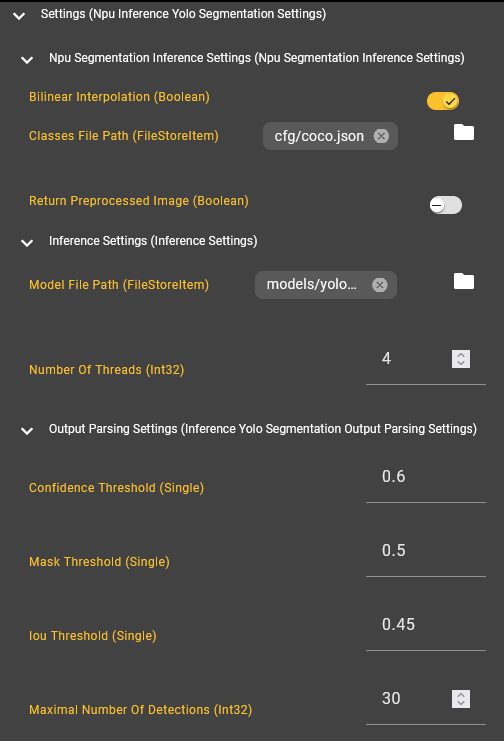

Beispielkonfiguration einer ‘NPU Yolo Segmentation’ Komponente
Knoten
Im Workflow werden acht unterschiedliche Knoten zur Verfügung gestellt:
Detect Objects (ONNX)
Detect Objects (NPU)
Classify Image (ONNX)
Classify Image (NPU)
Segment Instances (ONNX)
Segment Instances (NPU)
Detect Code (ONNX)
Detect Code (NPU)
An diese müssen die entsprechenden Komponenten übergeben werden, sowie ein oder mehrere Bilder.
Die Bilder sollten unter ähnlichen Bedingungen aufgenommen werden wie die Trainingsdaten. Angewendete Vorverarbeitungsschritte vor dem Training sollten auch auf die Bilder vor der Eingabe in den Inferenzknoten durchgeführt werden.
Jeder der Knoten gibt nach der Inferenz die gefundenen Klassen aller eingegebenen Bilder, sowie Meldungen bezüglich des Inferenzergebnisses zurück. Zudem wird für jedes eingegebene Bild ein sogenanntes Raw Result erstellt. Diese unterscheiden sich entsprechend der durchgeführten Aufgabe:
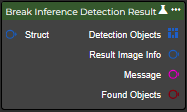
Inference Detection Result
Inference Classification Result
Inference Segmentation Result

Inference Code Detection Result
Die Raw Results enthalten alle validen Detektionen. Dabei kann es sich um Bounding Boxes, Objektklassen und zugehörige Confidence-Werte handeln, oder im Falle der Instanzsegmentierung um Masken der gefundenen Objekte. Zusätzlich wird das vorverarbeitete Bild und das eingegebene Bild mit eingezeichneten Bounding Boxes und Beschriftungen zurückgegeben. Analog zum Training mit Ultralytics werden die Eingabebilder automatisch auf die benötigte Größe unter Verwendung einer Letterbox skaliert. Das daraus resultierende Bild kann im Preprocessed Image eingesehen werden.
Der folgende Workflow zeigt beispielhaft die Verwendung eines YOLO-Modells zur Objekterkennung auf der NPU, sowie der anschließenden Speicherung der Ergebnisse in entsprechenden Variablen.